Originally published in the American Speech-Language-Hearing Association’s (ASHA) Perspectives on Augmentative and Alternative Communication, 20(1), 24-27 (paid subscription required for full access), here’s a brief history of my foray into augmentative and assistive communication (AAC).
Abstract
Glenda Watson Hyatt, web accessibility consultant, blogger, and user of AAC, shares her perspective on new mobile AAC technologies. A history of Glenda’s use of AAC is chronicled from her early low-tech strategies to her recent embracing of new mobile AAC technologies. She recounts purchasing an iPad and her early experiences attempting to use it as an AAC system in a variety of contexts. Strengths, weaknesses, and projections for the future are highlighted in this personal sharing of a user perspective.
A lack of oxygen for 6 minutes at birth resulted in the diagnosis “cerebral palsy athetoid quadriplegic.†My physical movements are jerky and involuntary; one body part or another is in constant motion. My left hand has some function, while my right is generally in a tightly clenched fist. I am not able to walk without support. My head control is tenuous, and swallowing takes a conscious effort.
“Functionally non-verbal†was also included in my diagnosis. It wasn’t that I couldn’t or didn’t communicate verbally, I did and do. My husband will attest to that fact, particularly when I’m fired up about something. It was the individuals beyond my family who didn’t understand what I was saying, as was evident early in my life, when in preschool a psychologist administered the Peabody Vocabulary Picture Test. I uttered one response that he could not understand. Finally, in complete desperation, he called in Mom, who was observing from the next room, to decipher what I was saying. “Roo roo.†The two of them gazed at the picture of a chicken. “Roo roo.†Suddenly it dawned on Mom. She asked, “Glenda, do you mean rooster?†Yes! The picture was obviously a rooster; the bird had a big, red comb. The experts expected me to offer the accepted response, chicken.
I learned to be quiet, except around my family and close friends. One day I came home from kindergarten nearly in tears. “Mommy, my knees hurt.†She sat me down and looked at my long-legged braces. The occupational therapist had put them on the wrong legs! Wearing shoes on the wrong feet causes some discomfort, but wearing heavy, metal braces on the wrong legs hurts. I knew he was putting the wrong brace on the wrong leg. However, I kept quiet because I thought he wouldn’t understand what I was saying. I didn’t want to create a hassle as he tried to decipher what I was telling him. After all, only people close to me understood Glenda-ish.
During my school years, there was an occasional attempt to introduce me to communication devices, which were quite primitive back then. I wasn’t interested. I felt those clumsy-looking “voice boxes†were more difficult to understand than I was. I was scared people would stop trying to understand me when I did talk. I didn’t want to be stopped from having my own voice being heard.
During my 7 years at university, my low-tech, no-batteries-required alphabet card became my security blanket. I didn’t leave my apartment without it. The alphabet card was handy for spelling out a word or two in a pinch and during lopsided conversations. My main form of communication was by notes I had typed beforehand, trying to anticipate all the information that would be needed in that particular conversation, which took some planning and forethought. I went through several dozen pads of Post-It notes during my university years. I dubbed them my talking papers.
Fast forward to 2005. I was active on the Social Planning and Research Council of British Columbia’s Board of Directors, and I was beginning to give presentations. The need for effective face-to-face communication was becoming more of an issue. I began wondering whether, with the advances in technologies, there was now a communication device that suited my needs. My husband Darrell called an old friend’s father who was the sales representative for a few communication devices, which he brought by our home for me to see. Despite the lure of the “shiny new objects,†I wasn’t overly sold on the fact that they were single-purpose devices, which would mean something else to lug around with me. And the price tags, ranging between $4,500 and $8,500, were definitely prohibitive.
I decided to go with a small Libretto laptop for roughly half (or less) of the price and with much more functionality than a communication device. I used it to take notes at conferences, to give several presentations, and to participate in some group discussions using the free text-to-speech software, E-triloquist.
I had some communication success with the Libretto and adding a $15 roll-up keyboard made typing easier. However, despite its small size, using it for spontaneous communication was clumsy. I had to unzip the laptop case, undo the Velcro straps, pull out the laptop, place it on a horizontal surface, boot it, and run the desired software before I could type out what I wanted to say. By then, the conversation had progressed and my contribution was old and disjointed. The laptop, although useful for some purposes, wasn’t really convenient for communication in the way I needed it to be. The Libretto did enable me to communicate a bit more, but it still wasn’t the ideal solution for me.
Fast forward again to April 2010. While in Chicago for a conference, I found my way to the Apple store and, after playing with an iPad for an hour, I pulled out my Visa to buy one, a month before the device was available in Canada. I also bought the Proloquo2Go (Assistiveware, 2009) app. Leaving the store, I had an intense feeling of buyer’s remorse. Would I be able to use the touch screen reliably with my shaky and jerky movements? Would the iPad really work for communication? Would it be another fad “shiny object†to gather dust? Had I just put $1,217.40 USD on my Visa for nothing? My stomach was in knots as I headed back to the hotel.
My buyer’s remorse was short-lived. After an hour of quality time with my iPad in my hotel room—enough time to unpack the thing, turn it on, and play around in Proloquo2Go and discover the onscreen keyboard and “speak†button—I met my two Deaf and hard-of-hearing friends for lunch. Typing in Proloquo2Go came in handy. A combination of lip reading, American Sign Language, and typing on the iPad, now there’s AAC on the fly!
Later that night, hanging out with other friends at the bar, the iPad’s back light and clear display made for easy reading in the dimly lit bar. The font size in the Proloquo2Go app was large enough to read from a comfortable distance.
The cool thing was, because the Holiday Inn and bar had WiFi, I had Internet access. When asked what I had been up to, I responded “problogging and ghost writing,†and I was able to show what I had written. I also shared the video of me ziplining across Robson Square in downtown Vancouver during the Winter Olympics. The iPad allowed for a deeper level of communication that would not have been possible with a single-function AAC device.
At another point during the conference, someone was having trouble figuring out what I was saying, and she asked, “Where’s your iPad?†In that moment, I felt a sense of normalcy and acceptance. Using my iPad, a Blackberry, or iPhone in a size I can actually use is not another thing that makes me different. It wasn’t using a strange, unfamiliar device to communicate with this group. People were drawn to it, because it was a “recognized†or “known†piece of technology, rather than being standoff-ish with an unknown communication device.
Even though the Proloquo2Go app has two options for communicating, the grid view and the onscreen keyboard, I see myself using the keyboard more where I have the freedom to use the words I use without needing to go hunting for them mid-conversation. For in-depth conversations, the grid option is too limiting and too much customization is needed to add the vocabulary that I use. Learning the organizational structure and memorizing where individual words are located to effectively communicate with this tool would require either training or several rainy Saturday afternoons curled up with my iPad.
What would be great is if the TextExpander (SmileOnMyMac LLC, 2010) app was compatible with the Proloquo2Go app. This could enable me to type something like “GH,†and it would automatically expand to “Glenda Watson Hyatt,†saving me time and not slowing down the conversation flow as much. A separate app would be better than an expansion feature within Proloque2Go, because then I could use the same shortcuts across apps on my iPad.
In addition to using the Proloquo2Go app, I have found other ways to use my iPad for communicating. Nominated for the local Entrepreneur of the Year’s High Tech Award, I needed to prepare a one-minute acceptance speech in the event of being announced as the finalist. Not eager to need to pull out my laptop, I wanted to be able to whip out my iPad for the quick task. I used my text-to-speech software TextAloud (NextUp Technologies, LLC, 2005) on my computer to create the audio file in the NeoSpeech voice of Kate, which I use in all of my presentations and which people have come to recognize as “my voice.†I then e-mailed it as an attachment to myself on my iPad. When I was announced as the winner, the Master of Ceremonies knelt beside me and held a microphone next to my iPad. I tapped play and Kate spoke my acceptance speech perfectly!
Being able to whip out my iPad from my handbag and having a choice of communication methods for when I’m on the go is life changing. Technology is finally catching up to my needs.
About the Author
 I work as a Web accessibility consultant with three levels of government, transit authorities, and non-profit organizations to improve accessibility of their websites for people with disabilities. I also combine Web accessibility expertise with a passion for blogging and first-hand experience living with a disability to work with bloggers to create an accessible blogosphere. Personally, I blog at Do It Myself Blog (www.doitmyselfblog.com) and Blog Accessibility (www.blogaccessibility.com). I have shared my life story in an autobiography titled I’ll Do It Myself (available from my blog and on the Amazon Kindle) to show others cerebral palsy is not a death sentence, but rather a life sentence.
I work as a Web accessibility consultant with three levels of government, transit authorities, and non-profit organizations to improve accessibility of their websites for people with disabilities. I also combine Web accessibility expertise with a passion for blogging and first-hand experience living with a disability to work with bloggers to create an accessible blogosphere. Personally, I blog at Do It Myself Blog (www.doitmyselfblog.com) and Blog Accessibility (www.blogaccessibility.com). I have shared my life story in an autobiography titled I’ll Do It Myself (available from my blog and on the Amazon Kindle) to show others cerebral palsy is not a death sentence, but rather a life sentence.
References
Proloquo2Go. (2009). AssistiveWare [Software]. Available from http://www.apple.com/iphone/apps-foriphone/
TextExpander. (2010). SmileOnMyMac LLC [Software]. Available from http://smilesoftware.com/TextExpander/touch/
TextAloud. (2005). NextUp Technologies LLC [Software]. Available from http://www.nextup.com/index.html
If you enjoyed this post, consider buying me a chai tea latte. Thanks kindly.

 In May, I had the opportunity to deliver two presentations. In both instances, I used the text-to-speech Proloquo4Text app on my iPad.
In May, I had the opportunity to deliver two presentations. In both instances, I used the text-to-speech Proloquo4Text app on my iPad. 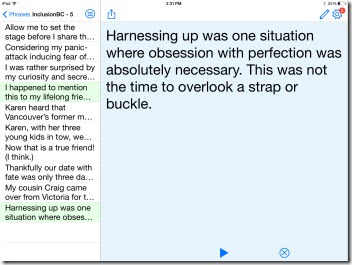
 Ever since buying my original iPad and, even more so, since my iPad Air, I have wondered if I could use the device to deliver a presentation.
Ever since buying my original iPad and, even more so, since my iPad Air, I have wondered if I could use the device to deliver a presentation. 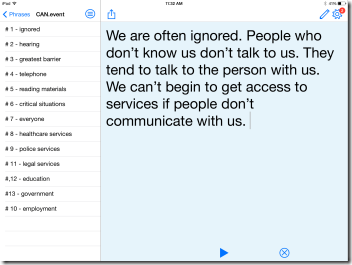
 Typing with only my left thumb is slow; painfully so when my mind is racing.
Typing with only my left thumb is slow; painfully so when my mind is racing. 


 Since he hadn’t seen me in my scooter coming at him, whipping out my low-tech, no-battery-required alphabet card would have been futile.
Since he hadn’t seen me in my scooter coming at him, whipping out my low-tech, no-battery-required alphabet card would have been futile. When he did get stuck on a word or when I wanted to give a somewhat longer response, I turned to the Proloquo2Go ap on my iPad and used the speak feature for the first time. As online, this iPad ap worked great in bridging our two disabilities.
When he did get stuck on a word or when I wanted to give a somewhat longer response, I turned to the Proloquo2Go ap on my iPad and used the speak feature for the first time. As online, this iPad ap worked great in bridging our two disabilities. Receive blog updates via
email
Receive blog updates via
email Subscribe via RSS
Subscribe via RSS



